| 세계 최초의 이미지-텍스트-음성 3중 모드 사전학습 모델 구축 | ||
|
||
 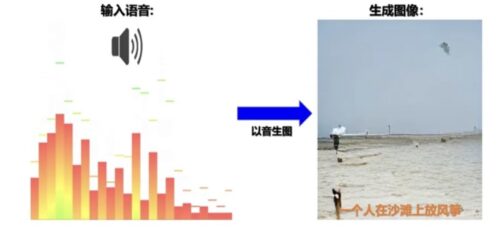 중국과학원 자동화연구소 연구팀은 세계 최초로 이미지-텍스트-음성 3중 모드 사전학습 모델을 구축하여 인공지능을 인간의 상상에 더 가깝게 했다. 기존의 다중 모드 사전학습 모델은 주변 환경에 일반적으로 존재하는 음성 정보를 무시하고 주로 “이미지와 텍스트” 또는 “영상과 텍스트” 두가지 모드만 고려하였으며 이해와 생성 능력을 겸비한 모델은 거의 없다, 때문에 생성 태스크와 이해 태스크에서 동시에 좋은 성과를 달성하기 어렵다. 연구팀은 이미지-텍스트-음성 3중 모드 사전학습 모델을 제안하고 텍스트, 음성, 이미지, 영상 등 다중 모드 내용을 결합하여 학습을 수행했다. 해당 모델은 단일 모드 인코더, 교차 모드 인코더 및 교차 모드 디코더로 구성되었고 각각 엔트리 레벨, 모드 레벨 및 샘플 레벨 등에 기반한 다차원, 다중 태스크 3단계 사전학습 자체감독 방식을 채택하였으며 이미지-텍스트-음성 3중 모드 데이터 간의 연관 특성과 교차 모드 전환 문제 주목하여 보다 광범위하고 다양한 다운스트림 태스크를 위한 모델 기반을 제공한다. 이미지-텍스트-음성 3중 모드 사전학습 모델은 이미지 식별, 음성 식별 등 교차 모드 이해 태스크를 달성할 수 있을 뿐만 아니라 텍스트로 이미지 생성, 이미지로 텍스트 생성, 음성으로 이미지 생성 등 교차 모드 생성 태스크도 달성할 수 있다. 아울러, 음성 모드를 도입한 다중 모드 사전학습 모델은 3중 모드의 통합된 표현을 직접 달성할 수 있으며 특히 최초로 “이미지로 음성 생성” 및 “음성으로 이미지 생성”을 달성했다. 또한, 영활한 자체감독 학습 프레임워크는 3가지 또는 임의의 2가지 약한 상관관계 데이터의 사전학습을 동시에 지원할 수 있으며 다중 모드 데이터 수집 및 정화 비용을 효과적으로 절감할 수 있으므로 사전학습 모델의 획기적인 진전을 이루었다. 이미지-텍스트-영상 3중 모드 사전학습 모델의 제안과 구축은 기존에 단일 모드로 단일 태스크를 대응하는 인공지능 개발 패러다임을 개변시켰고 텍스트, 음성, 이미지 및 영상 등 분야의 기본 태스크 성능을 크게 향상시켰으며 다중 모드 내용의 이해, 검색, 추천 및 문답, 음성 식별과 합성, 인간-컴퓨터 상호작용 및 자율주행 등 상업 응용에서 거대한 시장가치가 있다. 향후, “빅 데이터+대형 모델+ 다중 모드”의 태스크 통합 학습은 인공지능 기술 발전의 트렌드를 주도할 전망이다. 정보출처 : http://news.sciencenet.cn/htmlnews/2021/7/460961.shtm |
SEARCH
- 정책동향
- 이슈리포트
- 통계DB
- 통계DB